GO Database Guide
This page has the technical details regarding the GO database; if you are simply interested in browsing the database you may wish to proceed straight to AmiGO, the web interface for searching and browsing GO data.
Database Availability
Online access
The AmiGO browser and search engine provides web browser-based access to the GO database. As well as allowing users to search, browse, and download terms and annotations, AmiGO has analysis tools for further data processing.
Those familiar with MySQL can use GOOSE, the GO Online SQL Environment, a web interface for running SQL queries against the GO database. There are a number of sample queries for those unfamiliar with MySQL query syntax.
GO Database Mirrors
There are several sites that provide mirrors of the GO database accessible through a MySQL client (see the SQL section below for more on SQL queries of the GO database).
European Bioinformatics Institute (EBI)
The EBI mirror is of the full GO database: ontology data and all associations, both manual and electronic.
| Parameter | Value |
|---|---|
| host | mysql.ebi.ac.uk |
| user | go_select |
| password | amigo |
| database | go_latest |
| port | 4085 |
Ensembl
Ensembl provide builds of the full GO database going back several years. The GO databases are typically named ensembl_go_[ENSEMBL_BUILD_NO].
| Parameter | Value |
|---|---|
| host | ensembldb.ensembl.org |
| user | anonymous |
To connect to a database from a MySQL command line client, type the following:
mysql -h[host] -u[user] -p[password] -P[port] [database-name]
For example:
mysql -hmysql.ebi.ac.uk -ugo_select -pamigo -P4085 go_latest
Once connected you can use the SHOW DATABASES command to see available databases. To see when the database was built, use the command SELECT * FROM instance_data.
Access Policies
The GO database server and mirrors are a shared resource and thus we require data mining to be performed in a manner that allows others to utilize this resource at the same time. Any activity that mines the GO database using AmiGO or GOOSE must be controlled so that only one request is issued at a time. Users with greater needs than this should install a local copy of the database.
Local installation from pre-built database dumps
The GO database can be downloaded as a MySQL database dump and reconstituted on any system where MySQL is running. The data is also available as SQL statements for use with other database management systems; unfortunately we can only supply minimal support for non-MySQL databases.
Downloads and further details can be found on the GO database downloads page. Older builds of the database are available from the GO archives.
Build your own
You can create your own instance of a GO database, either by building one de novo, or by augmenting an existing build, e.g. by loading your own annotations or by adding other OBO ontologies. The go-dev software set contains the code and scripts required for these processes.
go-dev is a set of GO-related software and scripts, created and maintained by members of the GO Consortium. It can be downloaded via SVN. You may also need the gobo-dbic package for some applications.
To build a GO database from scratch, you will need a MySQL server, and the GO database SQL source, found in the directory sql of the go-dev software kit.
To load ontologies or data from OBO files or gene association files, you will need to install go-perl and go-db-perl (found in go-dev) and use the load scripts there.
Local GO mirror
Another way of creating your own instance of the GO database is by using a script provided in the go-dev distribution for creating GO mirrors: go_db_install.pl. Usage and examples are given by:
go-dev/trunk/go-db-perl/scripts/go_db_install.pl -h
For example, the following command loads the latest database dump into a database called "go_latest" on localhost:
go-dev/trunk/go-db-perl/scripts/go_db_install.pl -v -d localhost
This example will load the latest lite database dump into a database called "go_latest_lite" on localhost:
go-dev/trunk/go-db-perl/scripts/go_db_install.pl -i -e go_latest_lite -v -d localhost
This method is also useful for cron jobs. Please note that this method also creates a time stamp database with a suffix identical to the database name that you are loading.
Querying the Database
Querying via AmiGO
The most common way to query the database is via the AmiGO browser interface. The Advanced Query provides a reasonably flexible way to query the database, but far more powerful queries can be executed using SQL.
Querying in SQL
You can query the GO database using the SQL query language; either download and install the GO MySQL dump to query your local copy, or connect to one of the GO database mirror nodes. MySQL queries can be performed through the MySQL command line client, or by using software such as SquirrelSQL or MySQL Query Browser, one of the GUI tools from available from mysql.com.
If you are unsure as to how to construct your query, the best place to start is the example queries page on the GO wiki.
Querying via perl
You can connect to a local or remote MySQL installation using the API provided by go-perl and go-db-perl, part of the go-dev software set. The API can be used to get terms, subgraphs and annotated gene products, as well as to perform more complex analyses.
You can also use the perl API interactively through a perl shell, as follows (substituting connection details as appropriate):
GOshell.pl -d go_latest -dbuser go_select -dbauth amigo -port 4085 -h mysql.ebi.ac.uk
Type help for more instructions.
Querying via java
The GHOUL (GO Hibernate Object Layer) library provides an API for accessing GO through java calls and HQL queries.
The code is avaliable from the GO sourceforge project in the svn repository can be browsed here.
Type help for more instructions.
Alternate means of querying
There are also a few less conventional means of querying the database programmatically.
XML via DBStag
Nested XML can be automatically extracted from the database using DBStag. A number of SQL templates are available in the stag-templates directory in CVS.
SPARQL Endpoint
We have an experimental SPARQL Endpoint for querying an RDF view of the GO database. This service is highly experimental and not fully supported; if it proves useful it may be supported in future. Comments are welcome!
Database Schema
A relational schema specifies a collection of table definitions, providing structure for the data housed in the database instance. The schema for the GO database consists of tables for storing the terms and structure (as a graph) of the GO ontologies, along with gene product and annotation data.
Autodoc
See the automatically generated GO schema documentation.
The schema is partitioned into different modules or sub-schemas. This is purely a documentation convention. The go-graph module is for housing the ontology; the central tables are term and term2term. Annotations are stored in the go-association module; the main tables are association and gene_product. The GO database can also be enhanced with views; these are in the directory go-dev/sql/view. Autogenerated documentation is available for all tables and all views.
Schema Diagram (ER)
The database structure can also be seen in the entity-relationship diagram shown below; please note that the database schema used is dated June 2009.

Additional notes on the schema
Primary and foreign keys
As a convention, all tables in the schema use the column named id as the primary key, and foreign key columns are all named reference_id. All foreign keys are explicitly declared in the schema; however, MySQL drops these. This means you should always consult the documentation here, rather than relying on the MySQL DESCRIBE TABLES command or the CREATE TABLE commands in the database dump. The GO database schema page allows you to traverse primary and foreign key links via internal html page links.
All keys are numeric surrogate identifiers. They are meaningless, not consistent between builds, and bear no correspondence to public identifiers such as GO:0008050.
Terms as nodes in a graph
The central concept in OBO style ontologies and in the GO database is the graph. The terms are nodes in the graph, and the relationships between them are arcs (see the ontology structure documentation for more information). These is handled by the tables term and term2term.
The terms constituting the nodes in an ontology graph represent the kinds of entities that exist within the domain of that ontology. The edges in the graph represent the relations that hold between these entities. The edge types or relations in GO are drawn from the OBO Relation Ontology.
Note that these edge types or relations are also stored in the term table. This allows us to reuse the same schema structures, and potentially allows us to have hierarchies of relations, which may be required in the future.
Traversing Graphs
When performing ontology-oriented queries, it is often necessary to perform some kind of graph traversal. It is possible to use the term2term table to iterate through the graph, but this requires multiple database calls as MySQL does not support transitive operators such as Oracle's CONNECT BY. Most implementations of SQL do not support the kind of recursive querying required to answer queries such as "find all DNA binding genes".
This kind of query is possible with the GO database because we precompute the path from every node to all of its ancestors. This is known as the transitive closure of a relationship. This goes in the graph_path table, which also holds the distance between terms.
In particular, we calculate the reflexive transitive closure, which means that every term is related to itself (the distance between the terms is zero). In practical terms, this makes it easier to write queries such as "find all DNA binding genes", because such queries should return genes annotated directly to DNA binding, as well as to its children.
Note that we can use the same table to query for descendants as well as ancestors; it is simply a matter of switching around term1 and term2 in the graph_path query constraints.
The diagram below shows an example of the reflexive transitive closure of cellular pigment accumulation and its ancestors. The solid lines indicate direct is a relationships (stored in the term2term table); the dotted lines indicate the implied ancestral relationships (i.e. the closure), stored in the graph_path table.
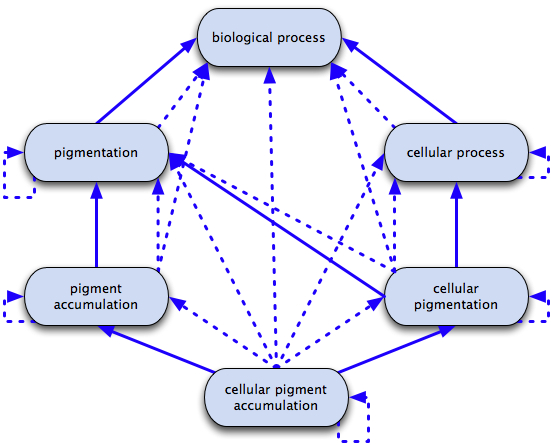
Transitive closure of cellular pigment accumulation and its ancestors.
Schema Source
The SQL source for the schema is maintained in go-dev, in the sql directory; see the sql/modules directory for the SQL DDL.
Finding out more
Contact
If you have specific questions, either technical or content-related, regarding the database, please contact the GO helpdesk.
The GO software group mailing list often hosts discussions of the database and related software. New list members must be approved before joining, but all conversations on the list are archived and can be viewed without a subscription.
Frequently Asked Questions
See the FAQ on the GO wiki.
Future extensions
There are a number of extensions to the schema planned over the coming years. These changes will be introduced in a way that retains backwards compatibility. You can see some examples of these in the form of unpopulated tables and columns in the database.
Deductive closure
A more advanced algorithm (e.g. that used by the OBO-Edit reasoner) for computing the graph_path table may be used in future, allowing us to discriminate paths of different edge types. Amongst other things it will help create relation-centric graph views.
Cross products
The schema already supports logical (complete) definitions via the complete relation qualifier, although these are not populated in the public GO database as the cross-products are still experiemntal.
For more background, see the logical definitions page on the GO wiki.
Similar database schemas
The GO schema is the predecessor of the ontology-based components of other bioinformatics schemas, including Chado, BioSQL and OBD. We have no plans to migrate to any of these schemas in the near future.